Table of Contents
Introduction
Training AI models takes a significant amount of time and can require the use of hundreds or even thousands of graphics cards working together, often in a data center, to complete the task. As an alternative to training new models from scratch or fine-tuning all of the parameters of an existing model, LoRAs were introduced. LoRA is an acronym for “Low-Rank Adaptation”, and is a method of fine-tuning models using a much smaller set of parameters and without fundamentally changing the model underneath. This allows for fine-tuning with just a fraction of the resources required compared to traditional fine-tuning.
Today, we will be exploring the performance of a variety of professional graphics cards when training LoRAs for use with Stable Diffusion. LoRAs are a popular way of guiding models like SD toward more specific and reliable outputs. For instance, instead of prompting for a “tank” and receiving whatever SD’s idea of a tank’s characteristics includes, you could include a LoRA trained on images of an “M1 Abrams” to output images of tanks that reliably mimic the features of that specific vehicle.
However, depending on the size of your dataset, training a LoRA can still require a large amount of compute time, often hours or potentially even days. Because of this, if you want to train LoRAs or explore other methods of fine-tuning models as anything more than a hobby, getting the right GPU can end up saving you a lot of time and frustration.

Image
In this article, we will be examining both the performance and VRAM requirements when training a standard LoRA model for SDXL within Ubuntu 22.04.3 using kohya_ss training scripts with bmaltais’s GUI. Although there are many more options available beyond standard LoRAs, such as LoHa, LoCon, iA3, etc, we’re more interested in measuring a baseline for performance, rather than optimizing for filesize, fidelity, or other factors. This also means that we won’t be focusing on the various settings that impact the behavior of the final product but don’t impact performance during training, such as learning rates.
We will specifically be looking at the Professional GPUs from NVIDIA (RTX) and AMD (Radeon PRO), as their large VRAM amounts and high number of compute cores make them ideal for professional AI workflows like this. We will, however, be testing consumer-grade GPUs in an upcoming article. They often don’t have the VRAM capacity necessary for this type of training and aren’t intended to be run at full load for extended periods of time, but their relatively low cost makes that type of card enticing for those who are just getting started in AI.
Test Setup
Threadripper PRO Test Platform
| CPU: AMD Threadripper PRO 5995WX 64-Core |
| CPU Cooler: Noctua NH-U14S TR4-SP3 (AMD TR4) |
| Motherboard: ASUS Pro WS WRX80E-SAGE SE WIFI BIOS Version: 1201 |
| RAM: 8x Micron DDR4-3200 16GB ECC Reg. (128GB total) |
| GPUs: AMD Radeon PRO W7900 Driver Version: 6.2.4-1683306.22.04 NVIDIA RTX 6000 Ada NVIDIA RTX A6000 NVIDIA RTX 5000 Ada NVIDIA RTX A5000 Driver Version: 535.129.03 |
| PSU: Super Flower LEADEX Platinum 1600W |
| Storage: Samsung 980 Pro 2TB |
| OS: Ubuntu 22.04.3 LTS |
Benchmark Software
| Kohya’s GUI v22.2.1 Python: 3.10.6 SD Model: SDXL AMD: PyTorch 2.1.1 + ROCm 5.6 NVIDIA: PyTorch 2.1.0 + CUDA 12.1 xFormers 0.0.22.post7 |
| Optimizer: Adafactor Arguments: scale_parameter=False, relative_step=False, warmup_init=False |
| Other arguments: network_train_unet_only, cache_text_encoder_outputs, cache_latents_to_disk |
To see how various Pro-level cards perform, we decided to look at a number of the top GPUs from NVIDIA, as well as the AMD Radeon PRO W7900. NVIDIA is definitely the top choice for AI workloads at the moment (which is why we are testing multiple NVIDIA GPUs), but AMD has been doing a lot of work recently to catch up in this space. NVIDIA is still our go-to recommendation in most situations, but we like to include at least one AMD GPU when we can in order to keep tabs on their progress.
If you have an AMD GPU and you’re interested in utilizing ROCm for training LoRAs and other ML tasks, we recommend following AMD’s guide for ROCm installation to make sure that your system has ROCm installed and configured correctly.
After confirming that ROCm was installed correctly, we moved on to setting up two virtual environments (one AMD and one NVIDIA) for kohya_ss using conda, cloning the repository, and installing the requirements. By default, a CUDA-based version of PyTorch is installed, so for the AMD virtual environment, we uninstalled that version and installed the ROCm version instead.
Once the correct version of PyTorch is installed, we’re ready to configure and run kohya_ss!
We decided to train an SDXL LoRA with the base model provided by StabilityAI using a set of thirteen photos of myself, resized to 1024×1024 each, matching the default image size of SDXL. Since we’re not concerned about the quality of the output, we’re not using any captions or regularization images.
Because we’re training on relatively large images, without the proper configuration, even GPUs with 48GB of VRAM can run out of memory during training. One of the most impactful settings to enable is some form of Cross-Attention, either SDPA or xFormers. We have tested the AMD cards with SDPA enabled, and the NVIDIA cards with both SPDA and xFormers.
Following recommendations for SDXL training, we enabled the following settings: network_train_unet_only, cache_text_encoder_outputs, cache_latents_to_disk
Thankfully, these options not only save some VRAM but also improve training speed as well.
Gradient checkpointing can be used to significantly reduce VRAM usage, but it comes with a notable performance loss. None of the GPUs we tested here required the use of gradient checkpointing, however, as they have more than enough VRAM.
Because we found that the reported speeds and VRAM usage leveled out after a couple of minutes of training and additional epochs yielded identical results, we chose to test each GPU with 1 epoch of 40 steps per image, for a total of 520 steps using a batch size of 1.
Finally, we used the Adafactor optimizer with the following arguments: scale_parameter=False, relative_step=False, warmup_init=False


Performance
System Image
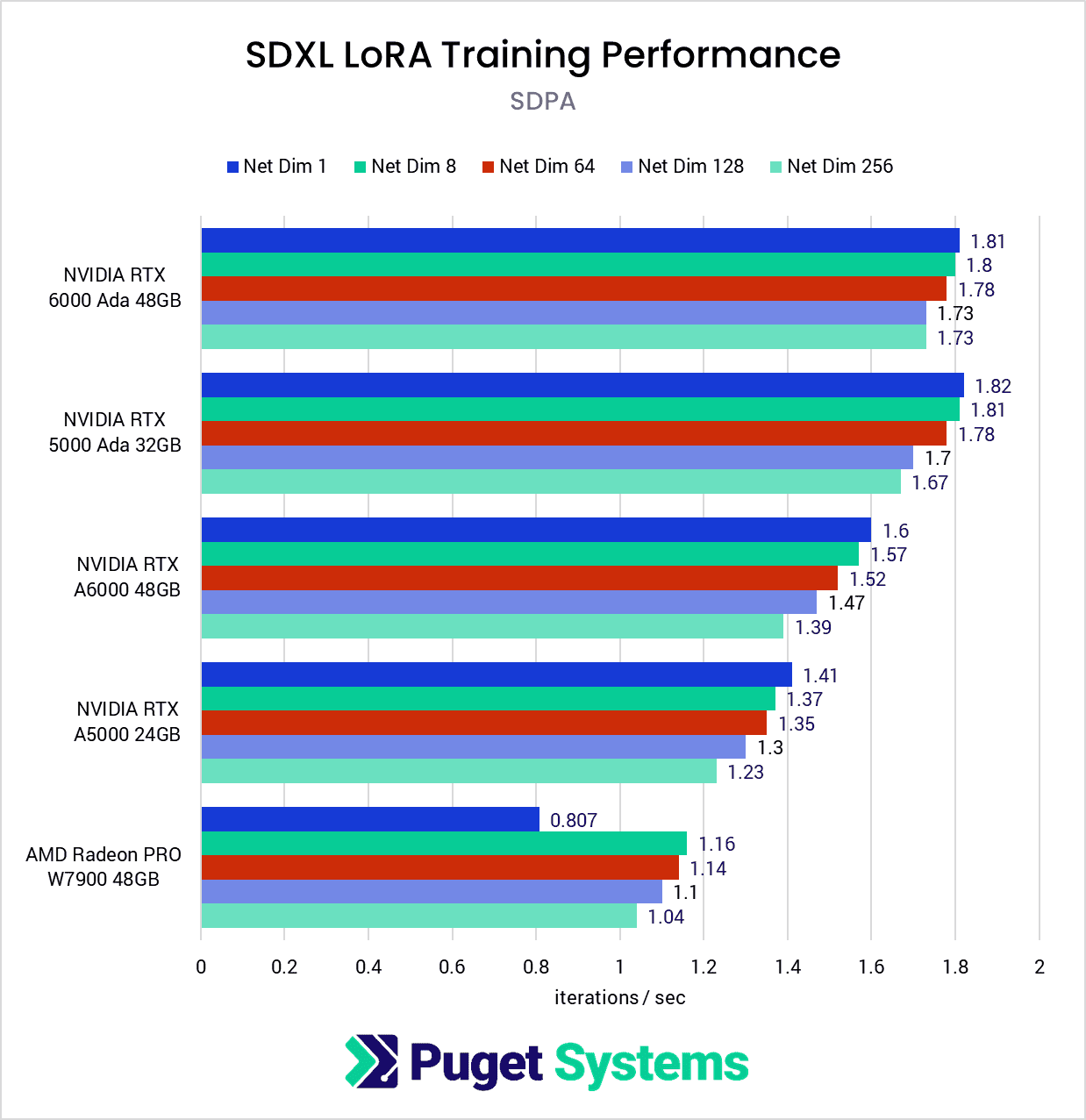
By and large, we didn’t uncover any anomalies during the SDPA performance testing, except for the poor performance we found for the AMD Radeon PRO W7900 when using Network Dimension 1. Typically, we find Net Dim 1 produces the highest iterations per second, but for some reason, the W7900 struggled at this level.
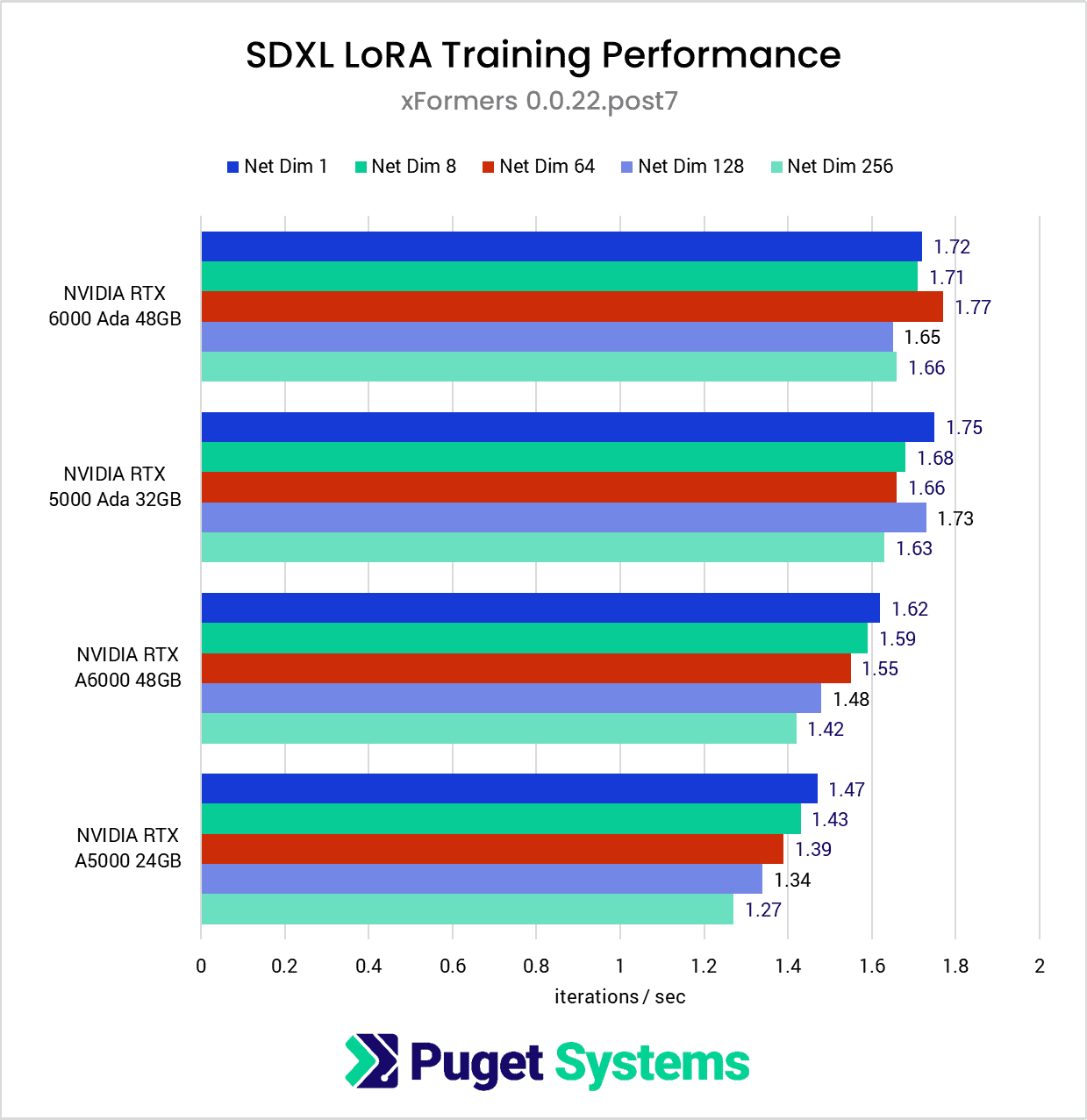
Although xFormers is not available for AMD GPUs, we decided to test the NVIDIA side with xFormers (chart #2) and found some interesting results. Instead of decreased performance as Network Dimensions increase, the latest Ada generation cards get a slight performance bump at certain levels: the RTX 6000 Ada sped up at Net Dim 64 and the RTX 5000 Ada at Net Dim 128. However, overall performance for the Ada generation is better with SPDA than xFormers, so there doesn’t seem to be much reason to use xFormers with these cards for LoRA training.
For the previous generation of NVIDIA cards, we found a very slight performance boost with xFormers over SDPA, so it may be worth using xFormers over SDPA for these cards.
The W7900’s performance trailed behind all of the NVIDIA cards tested here, with an average performance difference of about 55-65% compared to the 6000 Ada.
VRAM Usage
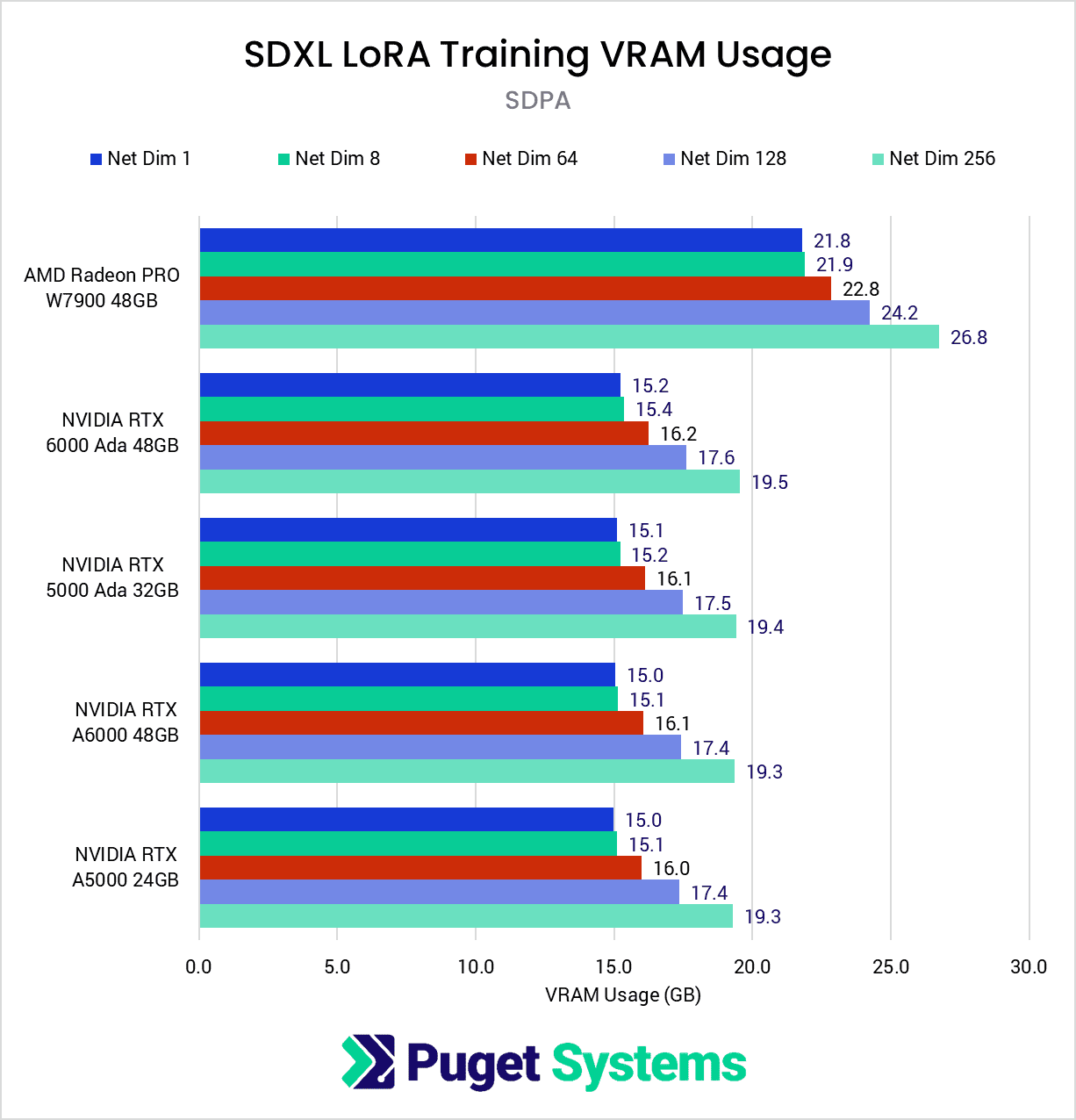
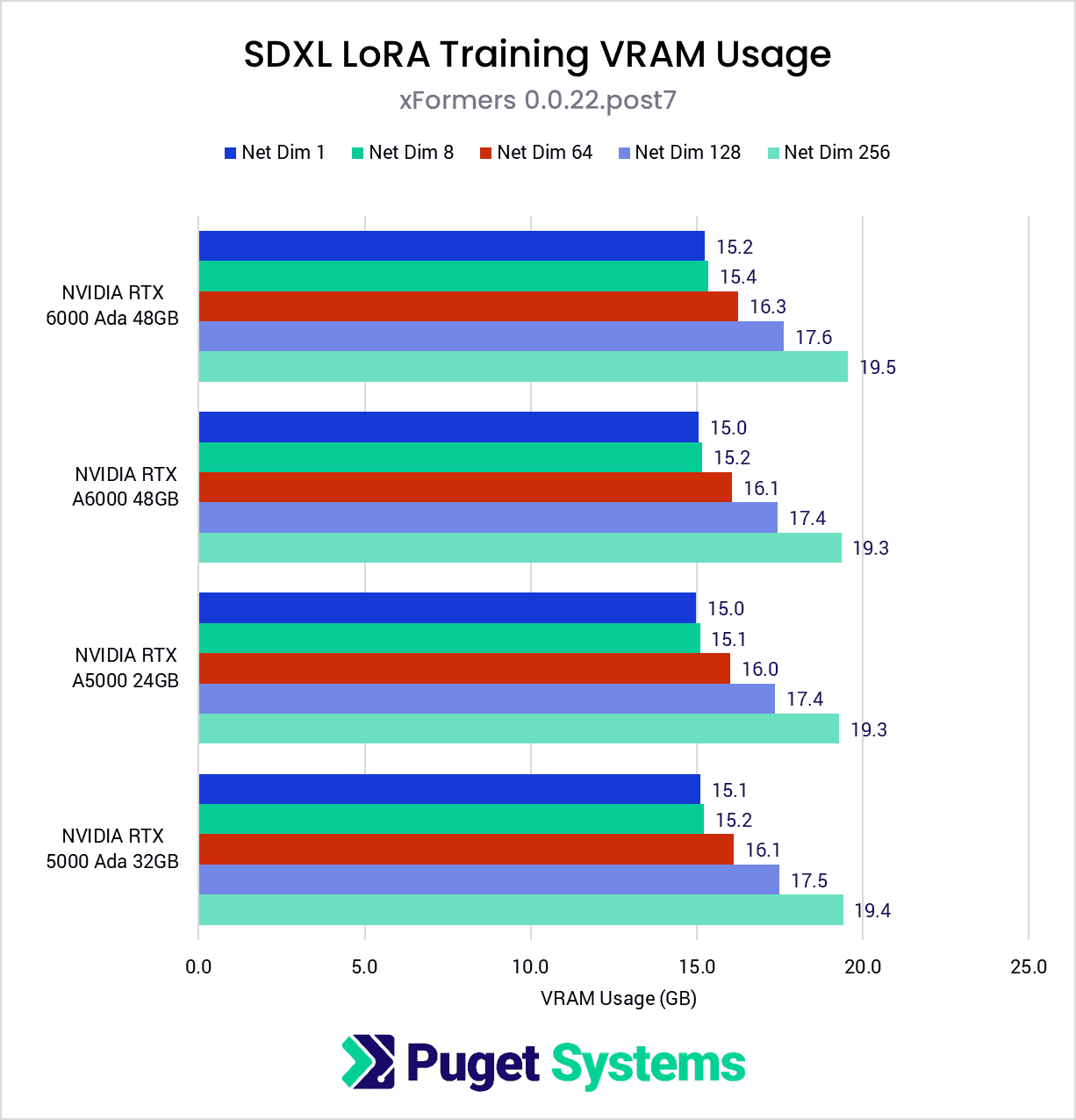
System Image
With a dataset of large images like these (1024×1024), VRAM usage is quite high. As expected, we found that VRAM use increased along with Network Dimensions. There was not a significant difference in VRAM usage between SDPA and xFormers, but we did find that the AMD Radeon W7900 used about 7GB more VRAM at every level than the NVIDIA GPUs at every level.
On the NVIDIA side, it was pleasing to find that the VRAM usage did not exceed 20GB, which is good news for those with 24GB GPUs. Based on this testing, it seems likely that NVIDIA GPUs with 24GB VRAM will have no trouble training SDXL LoRAs without the use of gradient checkpointing. However, if during our upcoming consumer-level GPU testing we find that AMD’s higher VRAM usage holds true for those models as well, then higher Network Dimensions will likely require the use of gradient checkpointing when training SDXL LoRAs, which will incur a performance penalty.
Conclusion
It’s been great to see the strides that AMD has made with the ROCm ecosystem, particularly in the second half of 2023, and it’s now easier than ever to utilize AMD GPUs for ML tasks. Although we still see NVIDIA holding the performance crown in this round of LoRA testing, it was refreshing to be able to compare the two manufacturers, and I’m confident that we’ll see performance improvements as ROCm support matures.
Any of the GPUs featured in this article are more than capable of training LoRAs, but if you’re someone who regularly trains LoRAs for Stable Diffusion, then the performance offered by the Ada-generation of NVIDIA GPUs could save you a significant amount of time spent training. These results show that the latest NVIDIA RTX 6000 Ada 48GB can be up to 24% faster than the previous generation NVIDIA RTX A6000 48GB, or 55% faster than AMD’s current best offering – the Radeon PRO W7900 48GB.
While these Pro-level cards are what you should be using to maximize performance and flexibility if you do this type of work regularly, they are certainly very expensive and can be difficult to justify if you are just starting out. In an upcoming article, we will continue this testing with a number of more affordable consumer-level GPUs, so stay tuned for more LoRA training results!
If you are looking for a workstation for AI and Scientific Computing, you can visit our solutions pages to view our recommended workstations for various software packages, our custom configuration page, or contact one of our technology consultants for help configuring a workstation that meets the specific needs of your unique workflow.
Looking for an AI and Scientific Computing workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.